

Share this
by THEOplayer on June 30, 2020
To provide online video at scale, we use HTTP Adaptive Streaming Protocols such as HLS or MPEG-DASH, which are both extremely popular. In this article, we will provide some insights on how Apple’s Low Latency HLS (or LL-HLS) works.
HTTP Live Streaming
First, let’s try to repeat the basis of HTTP Live Streaming (HLS) in one paragraph. It is fairly simple: a video stream is split up in small video segments, which are listed in a playlist file. A player is responsible to load the playlist, load the relevant segments, and repeat until the video is fully played. To allow for dynamic quality selection and avoid buffering, different playlists can be listed in a “master playlist”. This allows players to identify the ideal bitrate for the current network, and switch from one playlist to another.
For more details on how HLS works, check out our blog post here.
How Does LL-HLS Work?
Apple recently extended HLS in order to enable it for lower latency. When HLS was developed in 2009, scaling the streaming solution received the highest priority, which caused latency to be sacrificed. As latency has gained importance over the last few years, HLS was extended to LL-HLS. As Rome wasn’t built in a day, the specification wasn’t either. It took some weird twists and turns (you can read all about it in our previous blog post), but it was finalized 30th of April with an official update of the HLS specification.
Low Latency HLS, aims to provide the same scalability as HLS, but achieve it with a latency of 2-8s (compared to 24-30 second latencies with traditional solutions). In essence, the changes to the protocol are rather simple.
-
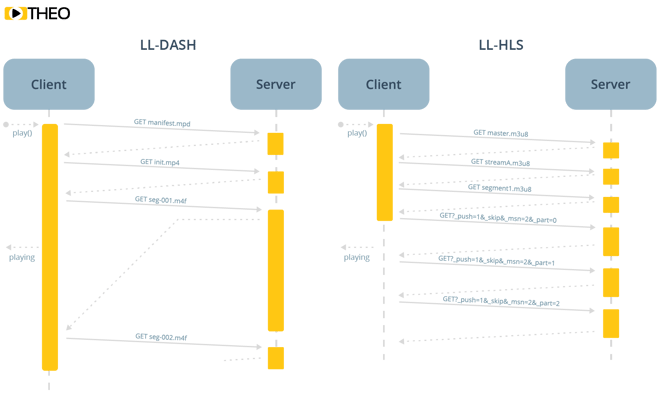
A segment is divided into “parts” which makes them something like “mini segments”. Each part is listed separately in the playlist. In contrast with segments, listed parts can disappear while the segments containing the same data remain available for a longer time.
-
A playlist can contain “Preload Hints” to allow a player to anticipate what data must be downloaded, which reduces overhead.
-
Servers get the option to provide unique identifiers for every version of a playlist, easing cacheability of the playlist and avoiding stale information in caching servers.
These three changes are at the core of the LL-HLS specification, so let’s go into each of these in some more detail (note: there are some other changes such as “delta playlists,” these are less crucial for the correct working of LL-HLS, but rather tend to optimize things).
HLS parts are in practice just “smaller segments”. They are noted with an “EXT-X-PART”-tag inside the playlist. As having a lot of segments (or parts) increases the size of the playlist significantly, parts are only to be listed close to the live edge. Parts also have no requirement to start with an IDR frame, meaning it is OK to have parts which cannot be played individually. This allows servers to publish media information while the segment is being generated, allowing players to fill up their buffers more efficiently. As a result, buffers on the player side can be significantly smaller compared to normal HLS, which in practice results in a reduced latency.

Parts can be addressed with unique URIs, or with byte-ranges. The use of byte-ranges in the spec allows for sending the segment as one file, out of which the parts can be separately addressed and requested.
Another new tag, called “EXT-X-PRELOAD-HINT”, provides an indication to the player which media data will be required to continue playback. It allows players to anticipate, and fire a request to the URI listed in the preload hint to get faster access. Servers should block requests for known preload hint data, and return it as soon as available. While this approach is not ideal from a server perspective, it makes things a lot simpler on the player side of things. Servers can still disable the blocking requests, but it is definitely recommended to support this capability. All of this sums up to a faster delivery of media data to players, reducing latency.
The third important update to the HLS specification is the ability to provide a unique naming sequence to media playlists through query parameters passed in the playlist URI. Using simple parameters, a playlist can be requested containing a specific segment or part. Players are recommended to request every playlist using these unique URIs. As a result, a server can quickly see what the player needs and provide an updated playlist if available. This capability is extended in such a way that the server can enable blocking requests on these playlists. Through this mechanism a server becomes empowered to provide the updated playlist as soon as it becomes available. Players detecting this capability can switch strategies to identify which media data will be needed in the future, decreasing the need for large buffers and… reducing additional latency.
As the protocol extension is backwards compatible with HLS, players which are not aware of LL-HLS capabilities will be able to still play the stream at a higher latency. This is important for devices which rely on old versions of player software (such as smart TVs and other connected devices) without the need of setting up a separate stream for devices capable of playing in low latency mode.
LL-HLS vs. LL-DASH
In contrast to LL-HLS, Low Latency DASH (LL-DASH), does not have the notion of parts. It does however have a notion of “chunks” or “fragments”. In LL-DASH, segments are split into smaller chunks (often containing a handful of frames), which are then delivered using HTTP chunked transfer encoding (CTE). This means the origin doesn’t have to wait until the segment is completely encoded before the first chunk can be sent to the player. There are some differences with the approach of LL-HLS, but in practice, it is quite similar.
A first difference is that LL-HLS parts are individually addressable, either as tiny files or as byte ranges in the complete segment. LL-DASH has an advantage here as it does not depend on a manifest update before the player can make sense of a new chunk. LL-HLS however allows for the flexibility to provide additional data on parts, such as marking where IDR-frames can be found and decoding can be started.
Interestingly, it is possible to reuse the same segments (and thus chunks and parts) for both LL-HLS and MPEG-DASH. In order to achieve this, segments should be created with large enough chunks/parts to support LL-HLS. By addressing the LL-HLS parts as byte-ranges inside a larger segment, the segment can be listed both in a LL-DASH manifest and an LL-HLS playlist. This way, each LL-HLS part can be provided to the client once it is available on the origin. Similarly, the origin for DASH, can provide the same data as a chunk to the player over CTE. While both a MPEG-DASH manifest and an HLS playlist would need to be generated, it allows duplicate storage of the media stream, which can lead to large cost savings.
When we look at compatibility, LL-HLS and LL-DASH are mostly supported on the same platforms, but there are some important nuances. In the case of iOS, we don’t expect LL-DASH to be used in production due to the restrictions on the App Store. The trickiest platforms to support are predicted to be the SmartTVs and some connected devices. On connected devices, especially older devices, if you are restricted to native/limited players, you could face problems with support for that low latency use case as older versions of the software don’t support it and software updates on those platforms are rare.

What to Expect with LL-HLS Moving Forward
The LL-HLS preliminary specification has been merged with the HLS standard, which means that it’s safe for vendors to start investing into LL-HLS adoption. We anticipate other vendors will aim to start supporting LL-HLS in production in September, as it’s likely that Apple will announce LL-HLS will be a part of iOS14, a part of their new iPhone releases. During Apple’s WWDC 2020, which kicked off on June 22nd, Roger Pantos hosted a session on LL-HLS, which you can watch here. In the session, Pantos announced that LL-HLS is coming out of beta and will be available for everyone in iOS 14, tvOS 14, watchOS 7, and macOS later this year, most likely during the iPhone Event in September. You can also read about the updates from a previous blog. At THEO, we already have beta players up and running. If you’re looking to get started on implementing, you can talk to our Low Latency experts.
What's Next?
Now that you know the specification and how it works, how can you implement LL-HLS today? In our next blog we discuss implementation of LL-HLS. Subscribe to our insights so you don’t miss it.
Interested in learning more about implementing a Low Latency HLS solution?

On-Demand Webinar: Apple’s LL-HLS is Finally Here
Hosted by our CTO Pieter-Jan Speelmans


Contact our LL-HLS Experts
