

Share this
by THEOplayer on July 9, 2020
In previous blogs we’ve covered how the LL-HLS spec has evolved and changed, as well as how it actually works. In this blog we want to discuss how the end-to-end solution would look, which use case the spec suits best and what THEO recommends for LL-HLS implementation.
How Does an End-to-End LL-HLS Solution Work?
An LL-HLS pipeline doesn’t differ much from other live streaming E2E solutions:
-
-
An encoder will compress a stream using H.264/H.265 (HEVC)/... codecs for video and AAC/AC-3/… codecs for audio.
-
From there, content can (optionally) be sent into a (often cloud hosted) transcoder to generate a full ABR ladder.
-
Those feeds will get sent to the packager. The packager is where a big part of the magic happens in the LL-HLS case. It is responsible to prepare the correct playlists with new tags and attributes, segments and LL-HLS parts, to be offered up to an origin.
-
The origin also received some additional responsibilities from an LL-HLS perspective. There are three major changes:
-
Where in the past, HLS did not require query parameters, the new HLS version allows for specific query parameters to be sent, which influence the presented playlist.
-
The origin also has to support blocking playlist reloads and blocking preload hints, meaning it has to be able to keep a request open for a longer time.
-
Finally, HTTP2 is required to be supported on the origin.
-
-
-
-
Once content is available on an origin, a player can request the relevant media information from a content delivery network (CDN), which in turn will request it from the origin. Note that for LL-HLS to work as intended, the CDN and player must also support HTTP2.
-

The player specifically will, of course, need to support LL-HLS, including its new playlists, executing blocking requests, and LL-HLS parts. Simplifying dramatically, for LL-HLS parts are the new segments, where players should buffer three parts (with a relevant IDR-frame) and playback can start. From there, a player remains responsible for everything it is doing from a normal HLS perspective, meaning refreshing the playlists, observing network capabilities and environments (and shifting to the correct variant stream when changes are detected), providing accessibility features such as subtitles and alternative audio tracks, … While all of these aspects have to be updated from an algorithmic perspective, if the player implements this well, it should require no change from an integration standpoint.
When should you use LL-HLS?
In situations where latency plays an important role in how viewers consume your content, LL-HLS can solve your latency problems, especially when streaming on Apple devices, LL-HLS is the best match. For example in the interactive scenario where you are following a live online lecture and you need to ask the teacher a question. If the glass-to-glass latency is high, your question may come many seconds later and the teacher could have moved to the next topic, resulting in loss of context.. Another example might be streaming a big game and hearing your neighbor cheer for a goal you haven’t seen on your screen yet, causing a spoiled experience. It’s also important to take into account second-screen viewing, or viewers that are reading updates from the game on their mobile phone and streaming the game on their TV, which can also cause a spoiled experience.
The biggest challenges we see for implementation with LL-HLS are in use cases like Server Side Ad Insertion (SSAI), Digital Rights Management (DRM) and subtitles. It is crucial to properly test if your use case requires subtitles, DRM or SSAI. As LL-HLS was finalized only recently, most vendors are not tackling these cases yet. As they represent some of the most important capabilities to make content accessible, protect and monetize, it is crucial you get this right. SSAI, subtitles, DRM, ABR and their implementation with LL-HLS are use cases we will go into more detail about in our next blog.
Another issue we still see is compatibility between server and player. There have been many versions of Low Latency HLS (you can read about the evolution of the spec in a previous blog), and the server and client must support the same version, not an older HTTP/2 PUSH-based version, or the intermediate draft version. While players and packaging vendors may have started implementation at different points in time, they might not cover all subtleties of the specification, for example the latest version making blocking playlist reload optional instead of it being mandatory in the intermediate draft version!
The Impact of Segment Size, GOP Size and Part Size
There are different parameters to keep in mind when implementing LL-HLS. In terms of latency, the three most important would be segment size, GOP size, and part size. Let’s discuss each one in a bit more detail:
Segment Size
For LL-HLS, Apple’s recommendation for segment size seems to be 6 seconds still, same as with traditional HLS. It is important to know that segment size will not impact latency when working with LL-HLS. With traditional HLS, protocol latency could be calculated as 4 times the segment size, but this calculation is no longer valid in the low latency scenario.
Segment size does impact the amount of parts which you will need to list in your playlist. As a result, it impacts the size of the playlist (and how much data must be loaded in parallel with the media data). Having long segments can as a result significantly increase the size of the playlist, causing overhead on the network and impacting streaming quality.

Another small impact of segment size is that it should be equal to or larger than your GOP size, which we will discuss next.
GOP Size
The GOP size, or size of your Group Of Pictures is one of the main parameters which determines how often a key frame (or IDR frame) will be available. A player requires a key frame to start decoding, meaning it will impact startup of your stream. Having large GOPs with only one key frame every 6 seconds for example, will mean that your player can start playback on a position once every six seconds. This doesn’t mean your startup time will be six seconds, but it might require your player to start at a higher latency. With the 6 second example, your average additional latency at the start will be 3 seconds, or an addition to your startup time of 3 seconds with a 6 seconds worst case scenario! (Our recommendation would however be to balance this out, and have the player intelligently determine how big of a delay in startup time is acceptable for a lower latency.)
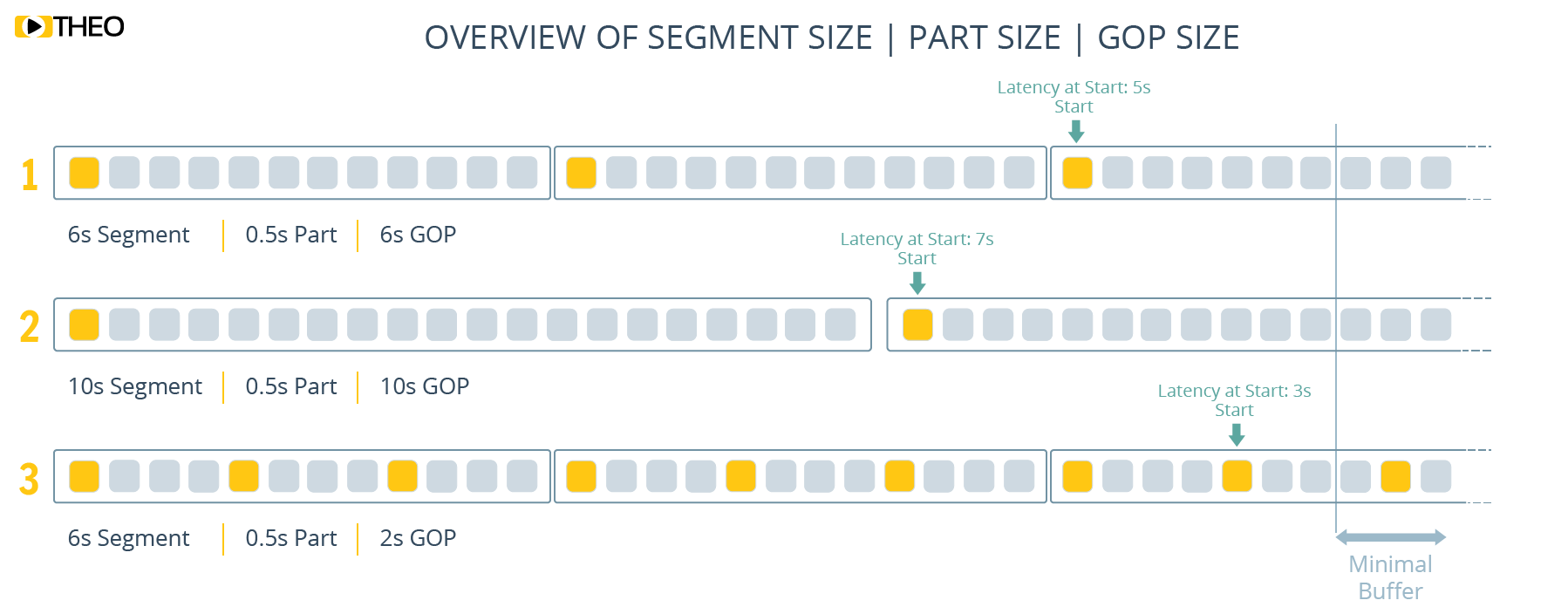 Based on this explanation, small GOP sizes seem extremely attractive. However, if you have a lot of key frames, it increases inefficiency in compression, which means you will use more bandwidth and streaming quality will go down. This effect becomes large when GOP sizes fall below 2s. The recommendation from THEO’s side would be to set your key frame interval to 2 to 3 seconds as it strikes a good balance between compression efficiency and viewer experience at startup.
Based on this explanation, small GOP sizes seem extremely attractive. However, if you have a lot of key frames, it increases inefficiency in compression, which means you will use more bandwidth and streaming quality will go down. This effect becomes large when GOP sizes fall below 2s. The recommendation from THEO’s side would be to set your key frame interval to 2 to 3 seconds as it strikes a good balance between compression efficiency and viewer experience at startup.

Part Size
Part size is the final parameter which has a very large impact on viewer experience with LL-HLS. In contrast to segment size, part size does have an impact on latency. Many people think that a smaller part size means a lower latency. This is true for part sizes larger than about 400ms. You must however keep in mind that the playlist has to be loaded for every part as well. This means reducing part size will increase metadata overhead. It also shows the delicate balance with segment size as described earlier. In field tests, we see that for part sizes smaller than 400ms latency seems to plateau as overhead becomes larger. This results in the end-to-end latency usually leveling out around 2-3 seconds. For this reason, we recommend part sizes between 400ms and 1s.
What About Buffer Size?
When talking about latency, buffer size is usually providing a large contribution. While the buffer ensures smooth playback, if the buffer is large it can bring overhead and increase latency. In LL-HLS, the buffer size largely depends on the part size. LL-HLS tells you that you should have a buffer of 3 part durations from the end of the playlist in the buffer. For example, when you have parts of 400ms, this will mean your buffer will target a size of 1.2s. Based on our tests, when your part size is higher, for example around 1 second per part, we notice buffer size can be slightly decreased without impact on user experience. As a baseline, you should never have a buffer less than 2 parts. If latency is extremely crucial for the use case, you could reduce the buffer, but then risk a bad quality of experience or buffering during playback.
How is THEO Implementing the New Specification?
At THEO, we have been closely following the LL-HLS specification. An initial version of the draft specification using H2 Push was developed, which evolved into a version with the intermediate specification, and which has now been updated to follow the final version of the specification. This player is under active testing with a wide range of different packager vendors and CDNs.
Are you a packager vendor who is interested in testing with us? Contact our LL-HLS experts today.
What's Next?
Low Latency is something that is constantly evolving, especially with LL-HLS where a lot of development is happening on all sides and keeping in mind Apple’s plan to launch it in their products in iOS 14 (set to launch in September). As the tools are not fully productized and matured yet is extremely important to test everything properly moving forward. As mentioned above, THEO currently has a beta player available that supports the most recent LL-HLS update. If you’re interested, don’t hesitate to contact our LL-HLS experts. In our next blog we will dive deeper into the implementation of LL-HLS with subtitles, ABR, SSAI and DRM.
Interested in learning more about implementing a Low Latency solution?

On-Demand Webinar: Apple’s LL-HLS is Finally Here
Hosted by our CTO Pieter-Jan Speelmans


Contact our LL-HLS Experts
