

When it comes to live video, it’s hard to deliver an actual, real live streaming experience. The latency problem is especially noticeable when video is distributed using online streaming platforms: you may have heard the stories of watching a sports event and hearing the neighbours cheer before seeing the start of an attack. In this article, we’ll go into details of the cause of the latency observed between an action being recorded and shown on the screen, and how it can be reduced to provide a better viewer experience to your viewers.
What is latency?
Latency is often described as “the time between cause and effect of some physical change”. Within a streaming environment, it is most easily experienced by measuring the time when something is recorded in real life and when it is seen on the screen, for example waving your hand in front of a camera and watching it move on the screen a certain time later.
Having a high latency on streams, and especially in interactive live experiences, can have a significant impact on user experience. Imagine a live stream with a latency of about 20s with an interactive chat box where the audience can ask questions: this would mean the person starring in the video could perform some action at a certain time T0. This image would show up on viewers’ screens 20s later. During this time, the broadcaster would simply continue with whatever he is doing. However, if a user would then type in and ask a question about the action at T0, showing up on the broadcaster’s screen, the broadcaster might be doing something completely different already, and have lost context. In return a (wrong) answer would still take another 20s before the answer gets back to the viewer!

Fig. 1 - What is latency
What causes latency?
An end-to-end media pipeline is complex and consists out of a range of components, each attributing to latency. Depending on the different components, and how this pipeline is configured, latency can be impacted significantly. Because the audio and video information needs to pass through this pipeline, it is prone to accumulate latency while passing through the components. When we would look at a common architecture, we would see there are a few big components contributing to this latency:
- Encoding & packaging: The latency introduced is very sensitive to configuration and quality of the output signal to be achieved. Certain streaming protocols can introduce additional latency as they can only output a chunk of media once it has been completely ingested.
- First mile upload: Uploading the packaged content to a CDN is often restrained by the business case. For example upload will have a significantly larger impact if this needs to be done over a wireless connection at an event, compared to a leased line set-up coming from a news studio.
- CDN propagation: In order to deliver content at scale, most media pipelines leverage content delivery networks. As a result, content needs to propagate between different caches, introducing additional latency.
- Last mile delivery: A user’s network connection can have a significant impact on latency. The user could be on a cabled network at his home, be connected to a wifi hotspot, or using his mobile connection in order to access the content. Also, depending on geographical location and position of the closest CDN endpoint, additional latency could be added.
- Player buffer: Video players have to buffer media in order to ensure smooth playback. Often the sizes of buffers are defined in media specifications, but in some cases there is some flexibility in this area. Also, optimising buffer configuration can go a long way given the significant impact of this component.

Fig. 2 - What causes latency
Latency vs Scalability vs Quality
When looking at latency, the impact of configuration of the different components in the media pipeline can be of utmost importance. Often configurations cannot be changed haphazardly, but have to be carefully considered depending on the business requirements. There are also a number of other factors at play when deciding this configuration, being scalability and quality.
- Scale: It used to be streaming protocols were severely limited in their scalability. Reaching growing audiences using protocols such as RTMP would require extremely complex server setups, and would result in massive scaling issues and systems collapsing as load increased. As a result, a new generation of streaming protocols became more common: HTTP based protocols. These protocols, such as HTTP Live Streaming (HLS), Microsoft Smooth Streaming, Adobe HTTP Dynamic Streaming (HDS) and later MPEG-DASH, make use of HTTP, and as a result can use standard HTTP caches and CDNs in order to scale. A downside of these protocols however, was that scalability was traded for latency, and latencies up to one minute became quite common.
- Quality: We see a similar trade-off when looking at quality of video compared to its latency. Achieving a higher quality for the end-user often results in higher bandwidth requirements due to higher resolutions and frame rates, or more time needed on the encoder side in order to shrink the bitstream at high quality. Furthermore, as already mentioned in the previous section, player buffers could be reduced in order to reduce latency. This however can significantly impact user experience as empty buffers will result in playback stalls, and are more likely to occur when a target buffer is small.
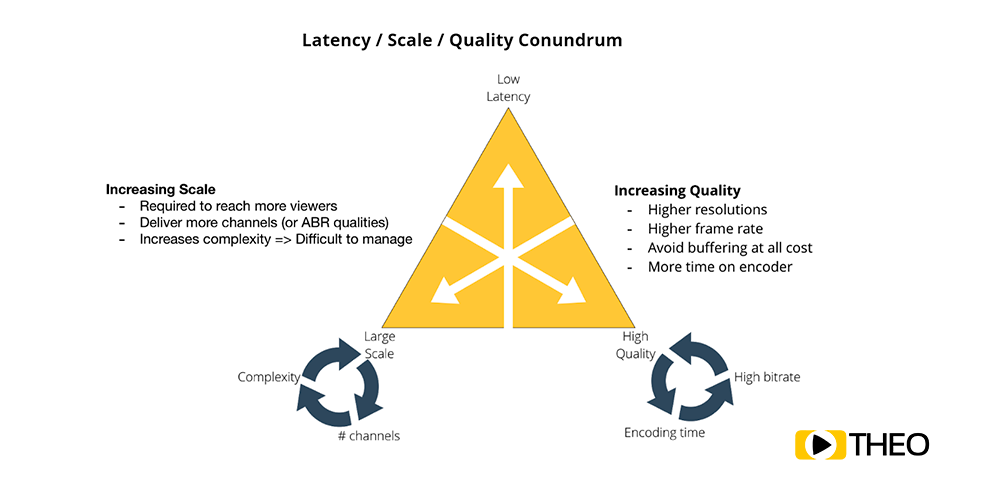
Fig. 3 - Latency vs Scalability vs Quality
While new technology and compression algorithms will shift the achieved results, and make lower latency ever achievable, finding the right balance within this latency trade-off triangle will always be important. Impact of technological improvements can already be seen in the advances made by cloud computing which significantly reduced scaling challenges, as well as new media codecs such as VP9, HEVC and AV1, reducing the required bandwidth significantly compared to older techniques.
Specific customer use cases are usually the best way to decide where on the latency trade-off triangle one should end up. When latency is crucial, for example for video conferencing, or video security monitoring, often scale or quality can be traded in. On the other side, when doing mass delivery of high quality media content in linear broadcast, latency can often be increased slightly. Ideal positions on this latency trade-off triangle will depend heavily on the targeted use case. In most situations, the position can however be shifted by configuration of the different components in the media pipeline.
Join latency, switch latency and glass-to-glass latency
We already made the mention of measuring latency between camera and screen by waving your hand and counting the delay. This technique was also at the base of the name “hand-waving latency” which is often used to describe latency. A similar explanation can be found for the name “glass-to-glass latency”, referring to the glass lenses of the camera and glass in the screen of your monitor, or “end-to-end latency”, referring to the start (capture) and end (display) of the media pipeline. However, there are a number of other factors which often influence latency, or are perceived as latency: join latency and switch latency.
While join and switch latency are not latency in the end-to-end kind of way, they do impact user experience, and in some configurations are actually a part of the end-to-end latency as a whole.
- Join latency is closely related to time to first frame, and is the time it takes to start playing a new stream. This delay is often the result of network delays like the number of network requests needed. Also, advanced media players allow you to configure if they should start playback as soon as they have the first data, or if they should wait until the start of a new chunk being published by the server, which results in a higher join latency, but a lower end-to-end latency.

Fig. 4 - Join Latency vs End to End Latency
- Switch latency on the other hand is the time needed to switch between different streams, for example adaptive bitrate channels. It is the time between a user (or algorithm) deciding there should be a switch, and the images of the new stream being shown. This latency is mostly related to the internal structure of the streaming protocol and the format of the group of pictures (GOP) which is being used. Playback can only be started when a new GOP starts, being at a keyframe. Most configurations however attempt to keep the number of keyframes low, and GOPs large as this often results in a lower bitrate for the same quality (or higher quality for the same bitrate).

Fig. 5 - What is Switch Latency
What is the current latency that is seen in the industry with different approaches
While optimising latency is surely important, a question we often get is “How low should your latency be?”. The answer will depend on the business case. In general, we advise our customers to make a number of changes to reduce latency already to be within the 18-30s range. This can be achieved with minimal effort and cost. For use cases where latency is crucial, it is interesting to have a look at recent advancements in protocols such as the newer Low Latency CMAF of Chunked CMAF standards being implemented by vendors. In case a business case requires ultra low latency, or real time latency, solutions such as RTMP or WebRTC are to be employed with a high cost when scaling and increasing quality.
- Typical latency: In this area, we see the average HLS and MPEG-DASH setups, suited for linear broadcast which is not time sensitive, and which will not have any interaction (both with the broadcaster, or other audiences over social media).
- Reduced latency: Reduced latency is achieved tweaking HLS and MPEG-DASH streams, reducing segment size and increasing infrastructure size. The approach is often used for live streaming news and sport events.
- Low latency: Low latency is often seen as a goal for every publisher as it allows for more interactive use cases.
- Ultra low latency: Makes it possible to have better interactivity, which feels close to real-time. While not suited for voice communication or conferencing, latencies between these bounds are often sufficiently low for common use cases.
- Real time communication: Having real time communication is crucial for use cases such as two-way conferencing and communication.

Fig. 6 - Latency according to the different protocols
What is next?
There is a broad scala on approaches and protocols being delivered to replace existing HLS and MPEG-DASH based pipelines in an attempt to reduce latency. There are a number of different types of solutions in play. While some solutions try to focus on first-mile protocols, others focus more on the last-mile protocols. For these protocols, the key focus points are:
- Video delivery between encoder and player is fast and efficient.
- Scaling distribution to large audiences is cost efficient.
- The approach works across device without additional requirements.
Keeping these in mind, there are four main approaches observed in the industry:
- Going back to RTMP: While this approach might seem strange due to the scaling issues which caused RTMP to be abandoned, technological advances in cloud infrastructure as well as RTMP support in CDNs have severely reduced pains of scaling older protocols. With RTMP support being reduced however due to the death of Flash and browsers stopping support, this approach feels like a less than optimal choice for the future. On top of that, more and more CDNs are stopping their RTMP support, which could cause a significant increase in costs for those left behind.
- WebRTC based: As in the name, WebRTC focusses on real time transfer of data and provides options for use cases such as conferencing tools. The trade-off made for this solution is mainly the quality aspect, where speed is deemed favourable over anything else. Additionally, most CDNs don’t provide support for WebRTC yet, and it requires a complex server setup in order to be deployed.
- Leverage WebSockets & HTTP/2.0: WebSockets provide a great approach to transfer data across the web fast. The biggest downside of this approach is the lack of standardisation for transferring media over this channel. Some companies have however implementations doing frame by frame transfer across this setup. Another question mark for this solution goes in the scale column as cost of scaling WebSockets can increase for massive numbers.
- MPEG-DASH/HLS based: Looking at standards, usage of MPEG-DASH or HLS and optimising feels like a good choice. Significant reductions in latency can already be achieved by simply reducing the size of segments, bringing latency down to the 5-12s range. Building further on this idea is the Low Latency CMAF (also called Chunked CMAF) specification, which is splitting individual segments in even smaller playable chunks. With these chunks being streamed out progressively using HTTP/1.1 chunked transport, latency can be reduced even further, and current implementations show latencies as low as 3-7 seconds giving stable playback. When capabilities of new protocols such as HTTP/2.0 or QUIC, which brings the web from TCP to UDP, are added in the mix, this approach will be a worthy alternative and likely gain significant traction in the market.
Another interesting option in this category is the relatively unstandardised “Low Latency HLS” or LHLS which was developed by Twitter. In this solution, chunked transport is used in order to deliver video chunks, similar to the low latency CMAF solution for MPEG-DASH. However, instead of using CMAF, this approach tends to use transport stream (TS) segments. The approach is in use with a number of other companies who control the full pipeline and appears to be a good fit for those who require a great level of flexibility and control.
In a next article we will go deeper into Low Latency CMAF and Chunked CMAF. Feel free to subscribe to our blog and receive an update when the new article is published.
As a frontrunner in player technology, THEOplayer already supports various low latency approaches such as Low Latency CMAF and LHLS and is continuously working to reduce latency and improve user experience. For any further questions on reducing latency, don’t hesitate to reach out to our team: they would be more than happy to guide you towards an optimal solution for your use cases.
